










 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


HDFS读写流程介绍,HDFS读数据和写数据的原理是什么?
更新时间:2020年12月01日18时29分 来源:传智教育 浏览次数:

Client(客户端)对HDFS中的数据进行读写操作,分别是Client从HDFS中查找数据,即为Read(读)数据;Client从HDFS中存储数据,即为Write(写)数据。下面我们对HDFS的读写流程进行详细的介绍。假设有一 个文件1.txt文件,大小为300M,这样就划分出3个数据块,如图1所示。
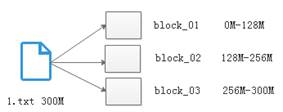
图1 文件划分情况
下面,我们借助图1所示的文件,分别讲解HDFS文件读数据和写数据的原理。
1.HDFS写数据原理
在我们把文件上传到HDFS系统中,HDFS究竟是如何存储到集群中去的,又是如何创建备份的,接下来我们来学习客户端向HDFS中的写数据的流程,如图2所示。
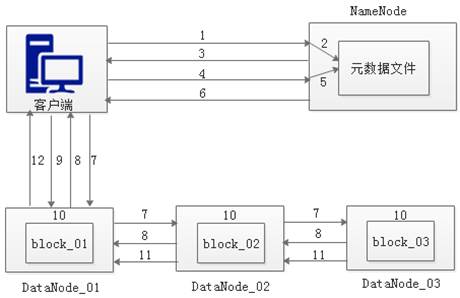
图2 HDFS写数据流程
从图2可以看出,HDFS中的写数据流程可以分为12个步骤,具体如下:
(1) 客户端发起文件上传请求,通过RPC(远程过程调用)与NameNode建立通讯。
(2) NameNode检查元数据文件的系统目录树。
(3) 若系统目录树的父目录不存在该文件相关信息,返回客户端可以上传文件。
(4) 客户端请求上传第一个Block数据块,以及数据块副本的数量(可以自定义副本数量,也可以使用集群规划的副本数量)。
(5) NameNode检测元数据文件中DataNode信息池,找到可用的数据节点(DataNode_01,DataNode_02,DataNode_03)。
(6) 将可用的数据节点的IP地址返回给客户端。
(7) 客户端请求3台节点中的一台服务器DataNode_01,进行传送数据(本质上是一个RPC调用,建立管道Pipeline),DataNode_01收到请求会继续调用服务器DataNode_02,然后服务器DataNode_02调用服务器DataNode_03。
(8) DataNode之间建立Pipeline后,逐个返回建立完毕信息。
(9) 客户端与DataNode建立数据传输流,开始发送数据包(数据是以数据包形式进行发送)。
(10) 客户端向DataNode_01上传第一个Block数据块,是以Packet为单位(默认64K),发送数据块。当DataNode_01收到一个Packet就会传给DataNode_02,DataNode_02传给DataNode_03; DataNode_01每传送一个Packet都会放入一个应答队列等待应答。
(11) 数据被分割成一个个Packet数据包在Pipeline上依次传输,而在Pipeline反方向上,将逐个发送Ack(命令正确应答),最终由Pipeline中第一个DataNode节点DataNode_01将Pipeline的 Ack信息发送给客户端。
(12) DataNode返回给客户端,第一个Block块传输完成。客户端则会再次请求NameNode上传第二个Block块和第三块到服务器上,重复上面的步骤,直到3个Block都上传完毕。
小提示:
Hadoop在设计时考虑到数据的安全与高效,数据文件默认在HDFS上存放三份,存储策略为本地一份,同机架内其他某一节点上一份,不同机架的某一节点上一份。
Ack:检验数据完整性的信息。
2.HDFS读数据流程
在前面我们已经知道客户端向HDFS写数据的流程,接下来我们来学习客户端从HDFS中读数据的流程,如图3所示。
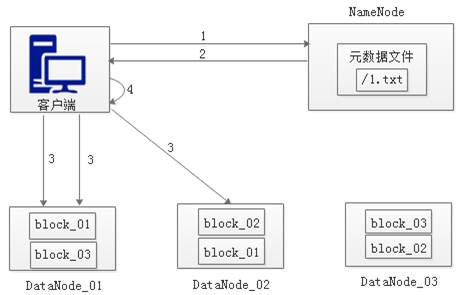
图3 HDFS读数据流程
从图3可以看出,HDFS中的读数据流程可以分为4个步骤,具体如下:
(1) 客户端向NameNode发起RPC请求,来获取请求文件Block数据块所在的位置。
(2) NameNode检测元数据文件,会视情况返回Block块信息或者全部Block块信息,对于每个Block块,NameNode都会返回含有该Block副本的DataNode地址。
(3) 客户端会选取排序靠前的DataNode来依次读取Block块(如果客户端本身就是DataNode,那么将从本地直接获取数据),每一个Block都会进行CheckSum(完整性验证),若文件不完整,则客户端会继续向NameNode获取下一批的Block列表,直到验证读取出来文件是完整的,则Block读取完毕。
(4) 客户端会把最终读取出来所有的Block块合并成一个完整的最终文件(例如:1.txt)。
小提示:
NameNode返回的DataNode地址,会按照集群拓扑结构得出DataNode与客户端的距离,然后进行排序。排序有两个规则:网络拓扑结构中距离客户端近的则靠前;心跳机制中超时汇报的DataNode状
猜你喜欢:
最新资讯




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
