










 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


创建RDD的2种方法【大数据开发】
更新时间:2022年03月07日18时36分 来源:传智教育 浏览次数:
Spark RDD 编程的程序入口对象是SparkContext对象(不论何种编程语言)。只有构建出SparkContext, 基于它才能执行后续的API调用和计算 。本质上, SparkContext对编程来说, 主要功能就是创建第一个RDD出来。
RDD的创建可以通过2种方式, 通过并行化集合创建( 本地对象转分布式RDD )和通过读取外部数据源( 读取文件)创建。
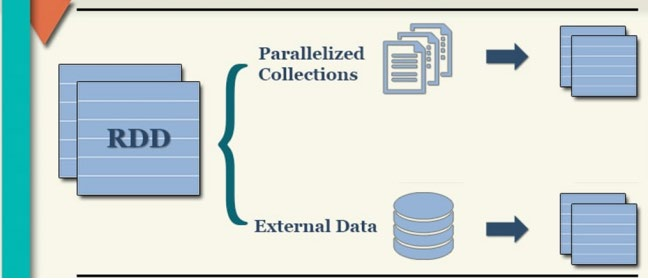
1.并行化创建
并行化创建是指将本地集合转向分布式RDD,这一步的创建是分布式的开端,将本地集合转化为分布式集合。
API如下
rdd=sparkcontext.parallelize(参数1,参数2) #参数1集合对象即可,比如list #参数2分区数完整代码:
# coding: utf8
from pyspark import SparkConf, SparkContext
if __name__ = '__main__':
# e.构建Spark执行环境
conf = SparkConf().setAppName("create rdd").\
setMaster("local[*]"]
sc = SparkContext(conf = conf)
# sc对象的parallelize方法, 可以将本地集合转换成RDD返回给你
data = [1, 2, 3, 4, 5, 6, 7, 8, 9]
rdd = sc.parallelize(data, numSlices = 3)
print(rdd.collect())
获取RDD分区数返回值是Int数字:getNumPartitions API
用法rdd.getNumPartitions()
2.读取文件创建
textFile API
这个API可以读取本地数据,也可以读取hdfs数据
使用方法:
sparkcontext.textFile(参数1,参数2) #参数1,必填,文件路径支持本地文件支持HDFS也支持一些比如S3协议 #参数2,可选,表示最小分区数量。 #注意:参数2话语权不足,spark有自己的判断,在它允许的范围内,参数2有效果,超出spark允许的范围,参数2失效完整代码
1f __nane__ = '__main__:
# B.构建Spark执行环境
conf = SparkConf().setAppNane("create rdd").\
setMaster("local[*]")
sc = SparkContext(conf=conf)
# textFile API 读取文件
rdd = sc.textFile(".…/data/words.txt", 1000)
print(rdd.getNumPartitions())
rdd2 = sc.textFile("hdfs://nodel:8020/input/words.txt", 1888)
#最小分区数给了1060,但是实际就开了85个, spark没有理会你要求最少1008的要求,而是尽是多开。
print(rdd2.getNumPartitions())
print(rdd2.collect())
注意:textFile除非有很明确的指向性,一般情况下,我们不是指分区参数。
读取文件的API,有个小文件读取专用场景:适合读取一堆小文件
用法:
sparkcontext.wholeTextFiles(参数1,参数2) #参数1,必填,文件路径支持本地文件支持HDFS也支持一些比如S3协议 #参数2,可选,表示最小分区数量。 #注意:参数2话语权不足,这个API分区数量最多也只能开到文件数量
这个API偏向于少量分区读取数据,因为这个API表明了自己是小文件读取专用,那么文件的数据很小。分区很多,导致shuffle的几率更高.所以尽量少分区读取数据。
猜你喜欢:
最新资讯
0
分享到:




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
