










 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


Python大数据培训:离散化连续数据
更新时间:2022年09月01日15时07分 来源:传智教育 浏览次数:
有时候我们会碰到这样的需求,例如,将有关年龄的数据进行离散化(分桶)或拆分为“面元”,直白来说,就是将年龄分成几个区间。Pandas的cut()函数能够实现离散化操作,该函数的语法格式如下:
pandas.cut(x, bins, right=True, labels=None, retbins=False,
precision=3, include_lowest=False, duplicates='raise')
上述函数中常用参数表示的含义如下:
(1)x:表示要分箱的数组,必须是一维的。
(2)bins:接收int和序列类型的数据。如果传入的是int类型的值,则表示在x范围内的等宽单元的数量(划分为多少个等间距区间);如果传入的是一个序列,则表示将x划分在指定的序列中,若不在此序列中,则为NaN。
(3)right:是否包含右端点,决定区间的开闭,默认为True。
(4)labels:用于生成区间的标签。
(5)retbins:是否返回bin。
(6)precision:精度,默认保留三位小数。
(7)include_lowest:是否包含左端点。
cut()函数会返回一个Categorical对象,我们可以将其看作一组表示面元名称的字符串,它包含了分组的数量以及不同分类的名称。
假设当前有一组年龄数据,需要将这组年龄数据划分为0~12岁、12~25岁、25~45岁、45~50岁、50岁以上共5种类型,图4-28是将这些数据经过面元划分前后的对比效果。
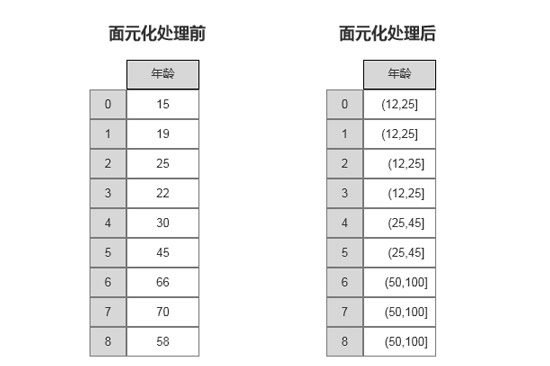
图4-28 面元化处理过程
最新资讯
0
分享到:




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
