










 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


全部 大数据新闻动态 大数据技术文章 大数据常见问题 技术问答
-
-
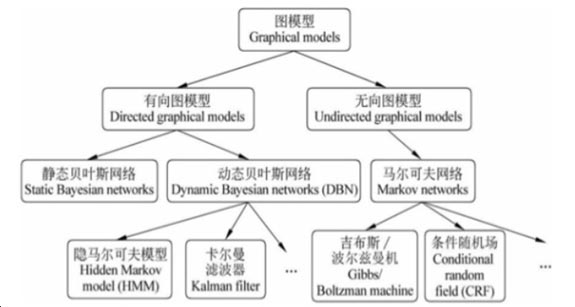
概率图模型[大数据培训]
概率图模型是在概率模型的基础上,使用了基于图的方法来表示概率分布,是一种通用化的不确定性知识表示和处理方法,在人工智能、机器学习和计算机视觉等领域有广阔的应用前景。 查看全文>>
大数据技术文章2019-10-14 |传智播客 |大数据概率图模型
-

SparkMllib如何解决回归问题?[大数据培训]
我们都参加过高考,据统计,高考的物理成绩确实与数学成绩有一定关系,但除此之外,还存在很多影响物理成绩的因素,例如:是否喜欢物理,用在物理上的时间等。而当我们主要考虑数学成绩对物理的影响时,就是要考察这两者之间的相关关系。 查看全文>>
大数据技术文章2019-10-10 |传智播客 |SparkMllib如何解决回归问题
-
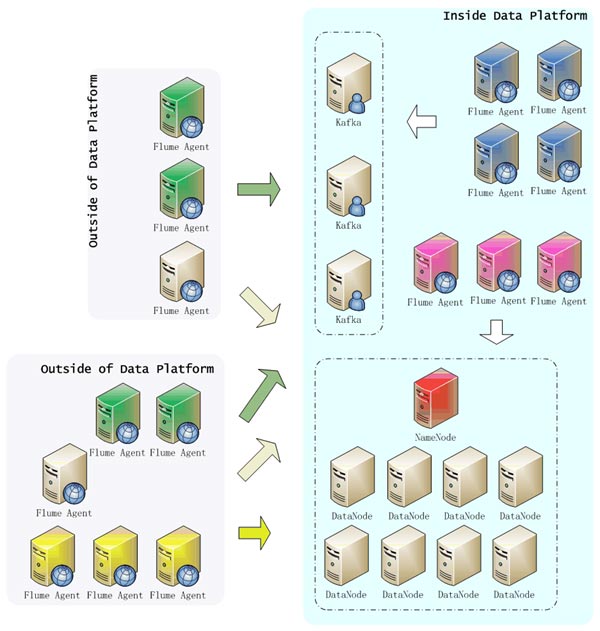
基于Flume设计实现分层日志收集系统有什么好处?【大数据技术】
基于Flume设计实现分层日志收集系统,到底有什么好处呢?我们可以先看一下,如果不分层,会带来哪些问题: 查看全文>>
大数据技术文章2019-10-10 |传智播客 |Flume分层日志收集系统
-

SparkMllib数值型特征基本处理方法介绍[大数据培训]
在SparkMllib中主要分为特征抽取、特征转化、特征选择,特别是在特征转化方面是从一个DataFrame转化为另外一个DataFrame,在数值型数据处理的时候我们对机器学习数据集中的样本和特征部分进行单独的处理,这里就涉及对样本的正则化操作和数值型特征的归一化和标准化的方法,今天就带大家理解这一部分的思考和认识。 查看全文>>
大数据技术文章2019-09-18 |传智播客 |SparkMllib数值型特征
-

kafka自定义拦截器实例教程[传智教育]
Producer拦截器(interceptor)是在Kafka 0.10版本被引入的,主要用于实现clients端的定制化控制逻辑。对于producer而言,interceptor使得用户在消息发送前以及producer回调逻辑前有机会对消息做一些定制化需求,比如修改消息等。同时,producer允许用户指定多个interceptor按序作用于同一条消息从而形成一个拦截链(interceptor chain)。 查看全文>>
大数据技术文章2019-09-17 |传智教育 |kafka自定义拦截器教程
-

MapReduce编程原理介绍[MapReduce开发必读]
Hadoop的MapReduce来源于Google公司的三篇论文中的MapReduce,其核心思想是“分而治之”。Map负责“分”,即把复杂的任务分解为若干个“简单的任务”来并行处理。可以进行拆分的前提是这些小任务可以并行计算,彼此间几乎没有依赖关系。Reduce负责“合”,即对map阶段的结果进行全局汇总。 查看全文>>
大数据技术文章2019-09-16 |传智播客 |MapReduce编程原理
-

Kafka常用的API有哪些?
Kafka是什么?Kafka最初由LinkedIn开发,是一款基于分区、多副本的分布式控制器,基于ZooKeeper协调。它最大的特点是能够实时处理大量数据,满足各种需求场景:如基于hadoop的批处理系统、低延迟实时系统、storm/spark流媒体引擎、web/nginx日志、访问日志、消息服务等,采用scala语言编写。LinkedIn在2010贡献了Apache基金会,并成为顶级开源项目。 查看全文>>
大数据技术文章2019-09-16 |传智播客 |Kafka api
-

正则化是什么意思? 正则化技术解析
正则化是广泛应用于机器学习和深度学习中的技术,它可以改善过拟合,降低结构风险,提高模型的泛化能力,有必要深入理解正则化技术。 查看全文>>
大数据技术文章2019-09-12 |传智播客 |正则化是什么
-

















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
