










 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


全部 Python+大数据新闻动态 Python+大数据技术文章 Python+大数据学习常见问题 技术问答
-
-

Python中字典的常见操作
Python为字典提供了一些很实用的内建方法,使用这些方法可以帮助读者在工作中应对涉及字典的问题,简化开发的步骤。此外,Python还提供了一些字典的常用操作。具体如下表: 查看全文>>
Python+大数据技术文章2021-11-05 |传智教育 |Python中字典的常见操作
-

如何在MySQL数据库中写入数据?
SparkSQL不仅能够查询MySQL数据库中的数据,还可以向表中插人新的数据,实现方式的具体代码如文件4-5所示。 查看全文>>
Python+大数据技术文章2021-11-01 |传智教育 |MySQL数据库写入数据
-

什么是Spark SQL?Spark SQL简介
Spark SQL的前身是Shark,Shark最初是美国加州大学伯克利分校的实验室开发的Spark生态系统的组件之一,它运行在Spark系统之上,Shark重用了Hive的工作机制,并直接继承了Hive的各个组件,Shark将SQL语句的转换从MapReduce作业替换成了Spark作业,虽然这样提高了计算效率,但由于Shark过于依赖Hive,因此在版本迭代时很难添加新的优化策略... 查看全文>>
Python+大数据技术文章2021-10-29 |传智教育 |什么是Spark SQL
-
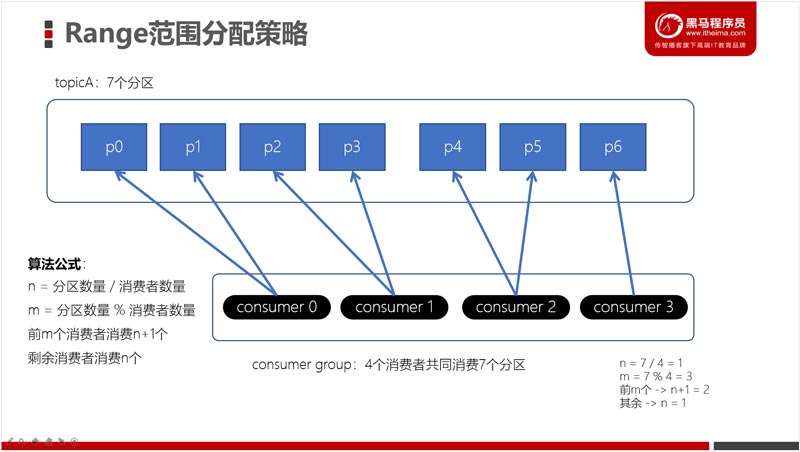
消费者分区分配策略:Stricky、Range、RoundRobin
Range范围分配策略是Kafka默认的分配策略,它可以确保每个消费者消费的分区数量是均衡的。注意:Rangle范围分配策略是针对每个Topic的。 查看全文>>
Python+大数据技术文章2021-10-29 |传智教育 |消费者分区分配策略,Stricky,Range,RoundRobin
-
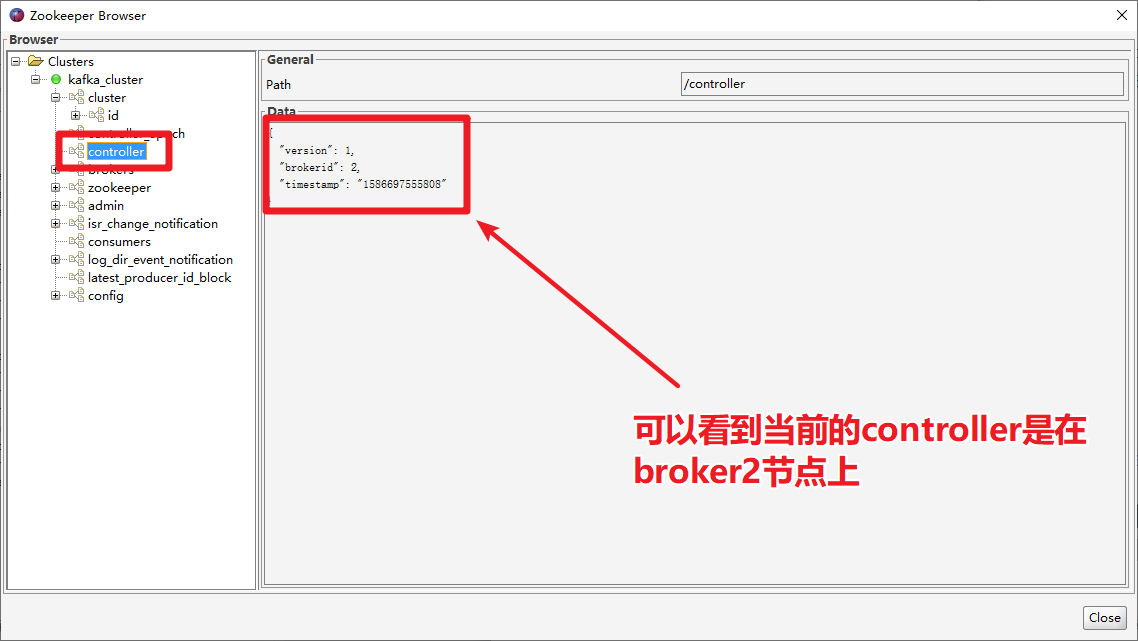
如果leader崩溃,Kafka怎样重新选举?
使用Kafka Eagle找到某个partition的leader,再找到leader所在的broker。在Linux中强制杀掉该Kafka的进程,然后观察leader的情况。通过观察,我们发现,leader在崩溃后,Kafka又从其他的follower中快速选举出来了leader。那么如何快速确定另外一个leader呢? 查看全文>>
Python+大数据技术文章2021-10-29 |传智教育 |leader崩溃Kafk的重新选举
-

TiDB为什么要需要调度?调度的基本需求是什么?
TiKV 集群是 TiDB 数据库的分布式 KV 存储引擎,数据以 Region 为单位进行复制和管理,每个 Region 会有多个 Replica(副本),这些 Replica 会分布在不同的 TiKV 节点上,其中 Leader 负责读/写,Follower 负责同步 Leader 发来的 raft log。了解了这些信息后,请思考下面这些问题: 查看全文>>
Python+大数据技术文章2021-10-21 |传智教育 |TiDB为什么要进行调度
-
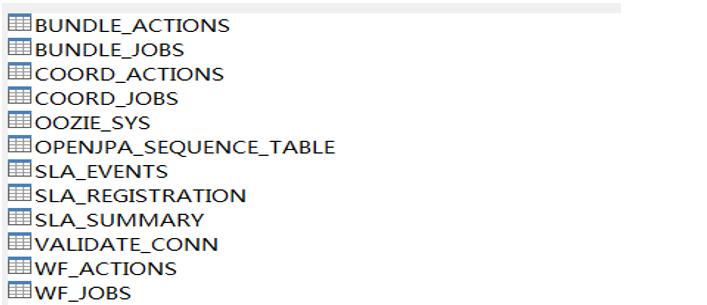
Apache Oozie安装图文教程
修改hadoop相关配置,修改hadoop的配置文件core-site.xml,hadoop.proxyuser.root.hosts 允许通过httpfs方式访问hdfs的主机名、域名,hadoop.proxyuser.root.groups允许访问的客户端的用户组 查看全文>>
Python+大数据技术文章2021-10-21 |传智教育 |Oozie安装教程
-

Oozie是什么?Oozie架构和基本原理介绍
Oozie是一个用来管理Hadoop生态圈job的工作流调度系统。由Cloudera公司贡献给Apache。Oozie是运行于Javaservlet容器上的一个javaweb应用。Oozie的目的是按照DAG(有向无环图)调度一系列的Map/Reduce或者Hive等任务。Oozie 工作流由hPDL(Hadoop Process Definition Language)定义(这是一种XML流程定义语言)。适用场景包括: 查看全文>>
Python+大数据技术文章2021-10-21 |传智教育 |Oozie是什么,Oozie架构,Oozie基本原理
-

















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
